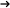

ADU Recap – Big Data with Catherine Baird, Ph.D.
By SOLTECH
I had the pleasure of listening to Catherine for the first time at an AxIO Security Round Table discussion. Although the event hosted several IT and business executives, you couldn’t help but pay special attention when Catherine spoke. She offered real opinions and advice based on her practical and extensive experience. When I learned that Catherine had agreed to speak at the Atlanta Developers Unit about Big Data, I was especially excited.
Our discussion started with Big Data basics. Catherine explained the difference between cloud computing where a machine had too much compute and too much data capacity for what was needed, so virtualization was used to share the compute and data capacity across multiple virtual servers all running on the same hardware. On the other hand with Big Data, one machine has too little compute and too little data capacity for what was needed, so the compute and data are distributed across multiple machines, all tied together by a new type of file system and operating system. Virtualization hence doesn’t make sense with Big Data and it is best to put it on “bare metal” to quote Catherine.
Catherine next talked about the 3 V’s of Big Data: Volume, Velocity and Variety. Not only is BigData about a lot of data, it is also about storing and using all kinds of data (video, audio, pictures, text messages, xml, etc.) and data that is in motion. We next went deeper into how the file system works, breaking files into chunks and then replicating those chunks many times – making your volume of data even bigger. Files are located using an URI (read about the difference between a URI and URL here), and for those of us so fond of SQL to access data, sorry. It’s a new world with MapReduce taking over.

Picture credit: http://saphanatutorial.com/hadoop-online-training-hadoop-basics/
The data replication made me frown a bit. Why replicate the data when one of your problems is too much data, especially if it isn’t for backup? Catherine explained the benefit was in the ability of a Big Data platform like Hadoop to access and work upon the different chunks of data at the same time, tremendously – and I mean tremendously speeding up processing times.
We talked about the current limitations of Big Data with a lack of security and no ability to extend the data over a WAN, and how those might be addressed in the future. We also talked about the “Pull Through” approach to Big Data. What Catherine meant by this is that don’t store data just to store it and hope something useful will come out of it later. Have an idea about what you are looking for first. The more grains of sand you have on a beach, the harder it is to find the one you want.
At the end of the discussion we talked about how to transition your career into Big Data and what the market needs now and in the future. Catherine encouraged us to install the tools, start small, gain some ground and be adventurous rather than scared. With a .Net background, I was a little disappointed to realize Big Data coding is all in Java. As a technologist you learn early on that change is certain, but it made me wonder how many .Net developers will learn Java now in order to stay relevant in the Big Data sphere?
All in all it was an incredible discussion. One where I felt like I was reading a cosmology book, trying to imagine multiple dimensions while wrapping my head around string theory.
Here are a few quotes from others who attended the meeting:
- Having worked on a number of data-intensive projects before, I had a comfortable handle on how much time things took in the RDBMS world (data transfer/export, transform, load, indexing, querying) but I find it staggering what kind of speed can be achieved in the Hadoop architecture on data structures/repositories that just dwarf what I felt were significant sizes (40+ TB vs. 20TB.) Catherine really helped establish an understanding of scale to the scope of “big data.”
- In all honesty, I was overwhelmed. I left last night realizing there’s an ocean of things to learn about Big Data, and all we did last night was dip our toes in the water. She did help define what Big Data is by what she called the “Three Vs”: (1) volume on the order of petabytes or higher, (2) variety in the structure (or lack thereof) in the data – meaning it could be absolutely any kind of data, from Facebook posts to Tweets to SMS messages to video files or whatever; (3) the high velocity in which the data needs to be processed by using a large number of replicas of the data.
- My two take – were: 1. A Practical definition for what big data is, by someone who knows and 2. The tremendous, and rare, opportunities that exist for monetizing this emerging tech in all areas; Development: by adding to the exploding Hadoop ecosystem, Services: expertise consulting, in-housing and management of client Big data initiatives and expertise placement/co-lo
To learn more about Catherine, you can visit her website or follow her on Twitter.
Cover Photo Credit: Tom Hall
